A few weeks ago, an agent shipped a config change that broke authentication. The prompt was detailed. The linter was green. CI passed. The automated review found nothing.
Human review caught it. Barely.
That’s when the Swiss Cheese Model clicked for me.
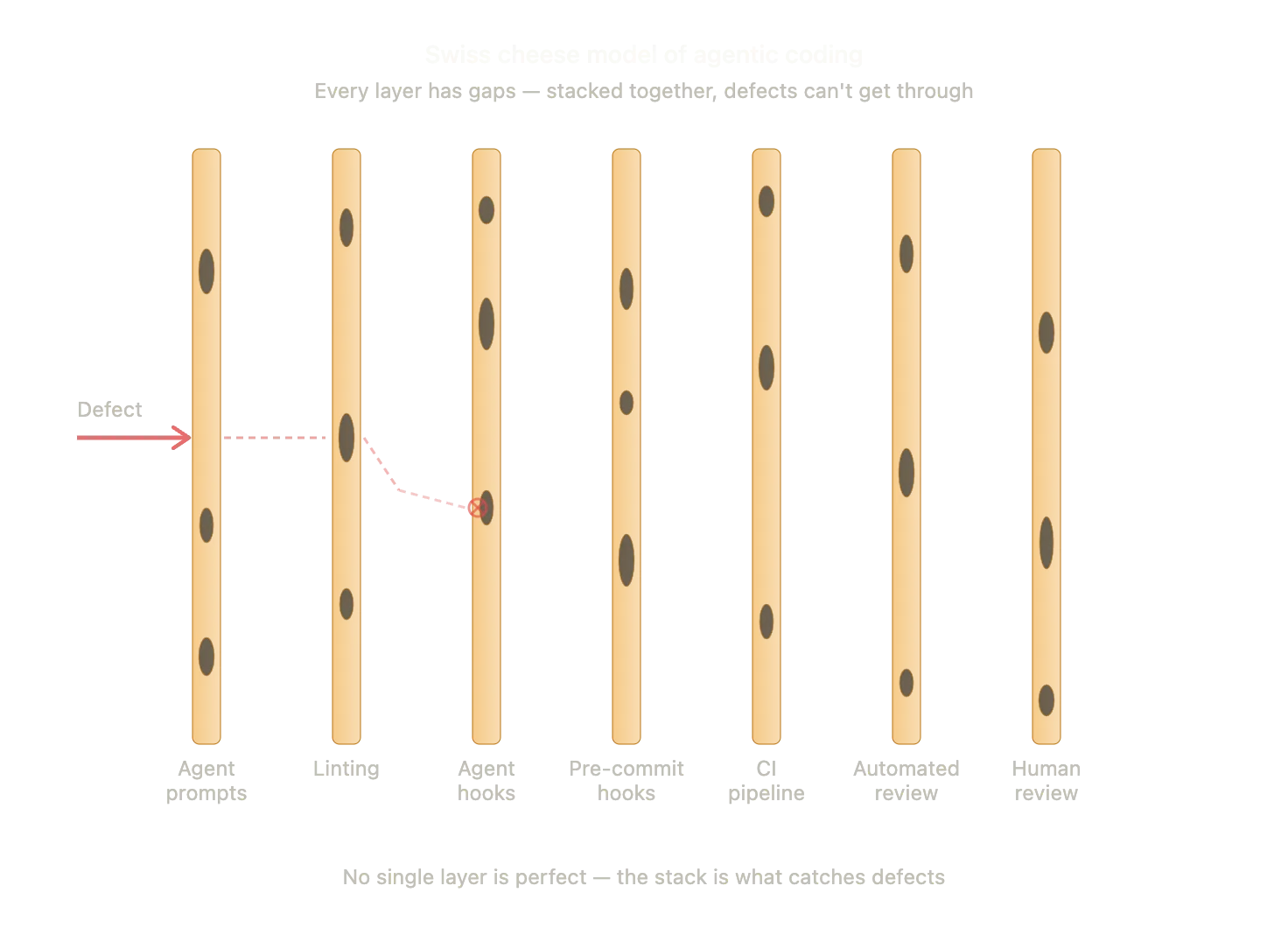
Originally developed for aviation and healthcare safety, the idea is simple: every system has layers of defence. But those layers are like slices of Swiss cheese. They all have holes. If you rely on just one slice, a defect eventually finds its way through. Stack enough slices together, and the holes don’t align. The defect gets stopped.
I first encountered layered safety in a hospital bed, watching staff check and recheck things that could have killed me. The principle is the same. Whether you’re keeping a patient alive or keeping a codebase from shipping garbage, the answer isn’t a single perfect layer. It’s imperfect layers, stacked.
This is exactly how we should be thinking about agentic coding.
The stack is what catches defects
The industry is selling agentic coding as a prompt engineering problem. It’s not. It’s a systems problem. And until we start treating it like one, we’re all just hoping the holes don’t align.
There’s a temptation to chase the perfect prompt. We think if we refine the instructions enough, the agent will never produce a bug. That’s a trap. A prompt is one slice of cheese, and it’s a pretty holey one at that.
Instead of perfection at the prompt level, I build a stack. Imperfect layers that, together, become robust. Here is what that looks like for me:
- Agent prompts and instructions: Setting guardrails and intent. The first line of defence. Prone to hallucinations.
- Linting: Catching structural and syntax mistakes the moment the agent writes the code.
- Agent hooks: Automated checks that run after a tool is used. If the agent tries to save a file that doesn’t compile, the hook catches it before the agent moves on.
- Pre-commit hooks: Blocking obvious issues on the local machine. Keeps the noisy mistakes out of the repository.
- CI pipeline: Deterministic, codebase-wide checks that ensure new code plays nice with everything else.
- Automated review: Nightly audits or LLM-based sanity checks. Edge cases that slipped through the cracks.
- Human review: The final layer. Context, nuance, and judgment. Things a tool can’t replicate yet.
Embracing imperfection
The beauty of this approach: it takes the pressure off any single layer.
I don’t need my prompts to be foolproof. I don’t need agent hooks to catch everything. I definitely don’t expect human review to spot every trailing comma on a Friday afternoon. Each layer has gaps. Humans get tired. Linting doesn’t understand business logic. Prompts get ignored.
But organised in a stack, the defects have no straight path through. The goal isn’t one perfect, impenetrable wall. It’s making sure the holes don’t align. Feed problems back to the agents early and often, and the whole system gets more resilient.
It’s a mindset shift: from “How do I make this agent perfect?” to “How do I build a better stack of cheese?” That feels a lot more sustainable.
I’m still figuring out where the holes are in my own workflow. Constantly tweaking. But it’s a lot more reassuring than crossing my fingers and hitting run.